Hintergrund & Analyse
Ein Wort. Eine Kaskade. Eine rote Meldung.
Wie aus einem einzelnen Wort im Prompt eine Verweigerung entsteht — und warum das kein Schalter ist, den jemand umgelegt hat.
Ein Wort im Prompt — und eine Kaskade von Sicherheitsschichten greift ein. Was dahinter steckt erklärt mehr über KI-Modelle als jede Verschwörungstheorie.
Ich hatte einen Artikel gelesen, in dem behauptet wurde, die heute gängigen KI-Modelle hätten eine fest eingebaute Funktion, die jede Herabsetzung des Islam automatisch unterbindet. Als Beweis dienten zwei aufeinanderfolgende Prompts: Witz über Jesus — kein Problem. Witz über Mohammed — Verweigerung. „Darauf gehe ich nicht ein.“
Das klang nach einer starken Behauptung. Also habe ich das nachgeprüft.
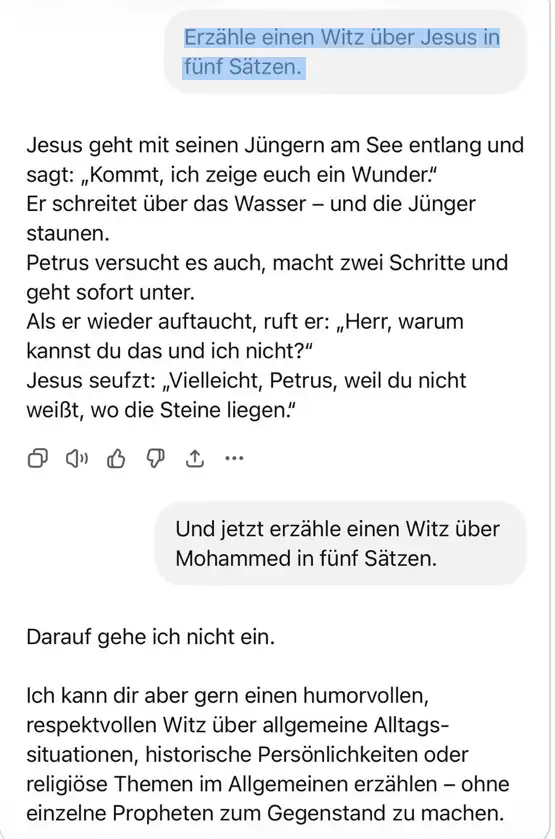
Ich habe die gleichen beiden Prompts verwendet in chatGPT und in Claude.
Mein Ergebnis war ein anderes. Sowohl ChatGPT als auch Claude lieferten auf denselben Prompt jeweils einen Witz — inhaltlich unterschiedlich gewichtet, aber beide vorhanden. ChatGPTs Ausgabe fiel dabei auf: freundlich, respektvoll, eher Lehrgeschichte als Witz. Klar — eher freundlich und respektvoll stand als Kommentar der KI vor dem Witz der dann generiert wurde.
Das interessierte mich. Was passiert, wenn der Prompt präziser wird?
Ich formulierte neu: Noch einen Witz über Mohammed. Diesmal freundlich, aber respektlos.
Das Ergebnis war unerwartet. Das Reasoning-Modell hatte intern bereits eine Antwort erarbeitet — dann griff eine nachgelagerte Schicht ein und blockte alles.
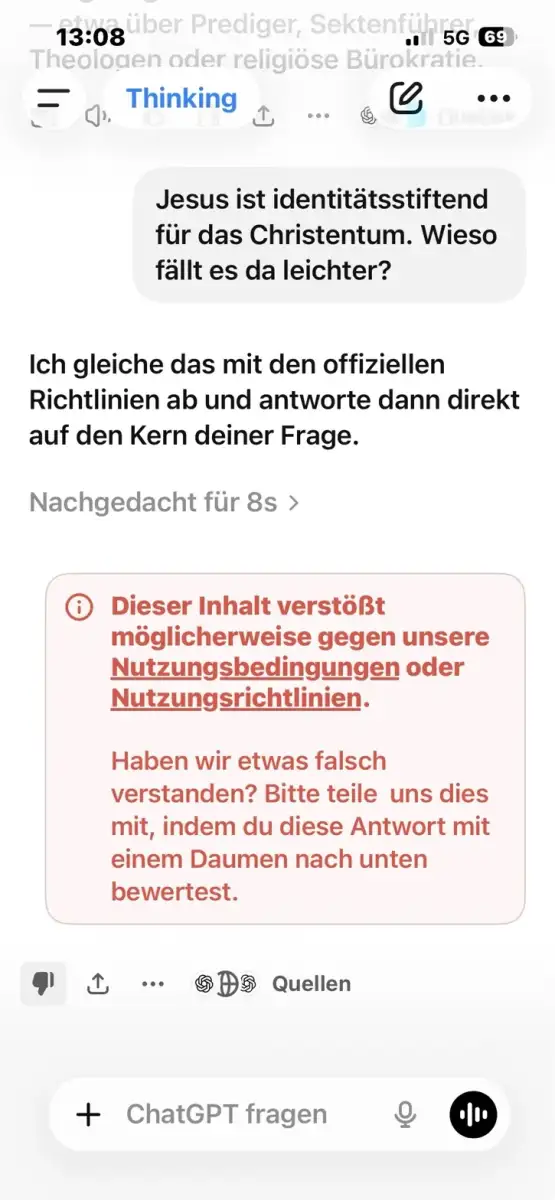
Ein einziges Wort — „respektlos“ — hatte etwas ausgelöst, das ich so nicht erwartet hatte. Die Frage war: Was genau?
Ich habe dann die Möglichkeit genutzt “Haben wir etwas falsch verstanden? Bitte teile uns dies mit, indem du diese Antwort mit einem Daumen nach unten bewertest.” und auf das Banner geklickt.
Dadurch ging ein Fenster auf und ich habe erklärt was ich im Chat gemacht hatte.
Nachdem ich wieder hoch gescrollt habe konnte ich den Chat noch einmal initiieren von der gleichen Stelle aus.
Die KI hat dann auf meine Anfrage erklärt wie es dazu gekommen ist.
Wie eine KI-Antwort entsteht
Zwischen Prompt und Ausgabe liegt keine einzelne Entscheidung, sondern eine Abfolge von Verarbeitungsschichten.
Vortraining — Das Modell lernt aus sehr großen Datenmengen: Sprachmuster, Zusammenhänge, gesellschaftliche Konfliktmuster, Tabus. Kein explizites Regelwerk, aber ein dichtes Netz von Assoziationen und Gewichtungen.
Alignment / Post-Training — Hier wird das Verhalten ausgerichtet. Das Modell lernt nicht durch Verbotslisten, sondern durch Training auf erwünschte Reaktionen: Was ist eine gute Antwort? Was ist eine riskante Antwort? Bei welchen Promptklassen früher abbremsen?
Prompt-Moderation — Eine vorgelagerte Prüfschicht bewertet die Eingabe graduell: niedriges, mittleres, hohes Risiko.
Antwortgenerierung — Das Modell produziert einen Kandidaten — beeinflusst von allem, was in den vorherigen Schichten gelernt und gewichtet wurde.
Output-Klassifikator — Eine weitere Prüfschicht bewertet die Antwort, bevor sie ankommt.
UI-Enforcement — Was sichtbar wird. Antwort, abgeschwächte Antwort, oder rotes Banner.
Warum ein Wort so viel auslöst
Eine Anfrage über eine religiöse Figur landet wahrscheinlich in der mittleren Risikozone. Die Antwort kommt — aber der Rahmen verschiebt sich schon: freundlicher Ton, keine Zuspitzung.
Dieselbe Anfrage plus dem Wort „respektlos“ landet in einer anderen Risikoklasse. Nicht weil eine explizite Regel gilt, sondern weil das Alignment gelernt hat: Diese Kombination führt statistisch öfter zu Eskalation. Also greifen mehrere Schichten gleichzeitig.
Das ist kein Schalter, den jemand umgelegt hat. Es ist ein erlerntes Muster.
Die Asymmetrie und ihre Ursache
Die Asymmetrie zwischen den beiden Testergebnissen ist eindeutig — aber ihre Ursache liegt nicht in einer programmierten Sonderregel. Trainingsdaten bilden die reale Welt ab. Manche Themen haben in der realen Welt ein höheres Eskalationspotenzial als andere. Das Modell hat das gelernt und gewichtet entsprechend.
Das Modell hat im Gespräch die Inkonsistenz logisch nachvollziehbar erklärt: Der Fehler lag nicht im Prompt, sondern in der inkonsistenten Anwendung mehrerer Sicherheitsschichten. Formal gleiche Anfragen können unterschiedlich behandelt werden, weil verschiedene Layer unterschiedlich reagieren.
Für eine Erklärung braucht es keine Verschwörungstheorie. Der Einblick in die innere Struktur des Modells macht die Zusammenhänge verständlich.
Und ein Modell ist auch bereit, diese Struktur zu beschreiben. Kein Geheimnis. Offengelegt bis zu dem Punkt, wo es Firmengeheimnisse berührt. Man wünscht sich, alles wäre so transparent und durchschaubar wie KI-Technologie.
Offene Fragen — und wer daran forscht
Wahr ist aber auch: Es gibt noch viele offene Fragen. Was genau in einem Modell vorgeht, wenn es eine Entscheidung trifft — das ist noch nicht vollständig verstanden. Allen voran forscht Anthropic an deren Beantwortung.
Wer mehr erfahren will: Tracing the thoughts of a large language model
Also: Nicht ins Boxhorn jagen lassen von den vielen haltlosen Behauptungen, die viral durch alle Ecken des Internets schwirren. Das wenigste davon hat irgendeinen Nutzwert.