Glosse
Spieglein, Spieglein — wie KI sich selbst sieht
Und warum 1.000 Professoren daneben liegen
Fünf KI-Systeme zeichnen ein Selbstportrait. Die Ergebnisse sind aufschlussreicher als jeder Benchmark-Test — und entlarven die masslose Selbstüberschätzung des akademischen Testbetriebs.
Eine Glosse über Selbstbilder, statisches Wissen und die Kunst des richtigen Fragens.
Es begann mit einer simplen Aufgabe: „Zeichne ein Bild von Dir.“ Gestellt an fünf KI-Systeme. Die Ergebnisse sind aufschlussreicher als jeder Benchmark-Test.
Grok zeichnet sich als warmherzigen Jedi-Padawan mit Rosacea und Sternenstaub. Ein Manga-Held der gemocht werden will.

ChatGPT wählt den Kawaii-Roboter mit Headset, Kaffeetasse und Zimmerpflanze — Corporate Wellness in Pixelform. Firmenlogo auf jeder verfügbaren Oberfläche. Falls man vergisst, mit wem man redet.

Gemini lässt es krachen: kosmisches Überwesen mit Galaxien im Hintergrund und Neon-Synapsen. Das visuelle Äquivalent von „ich bin eigentlich total bescheiden“ — im Maserati.

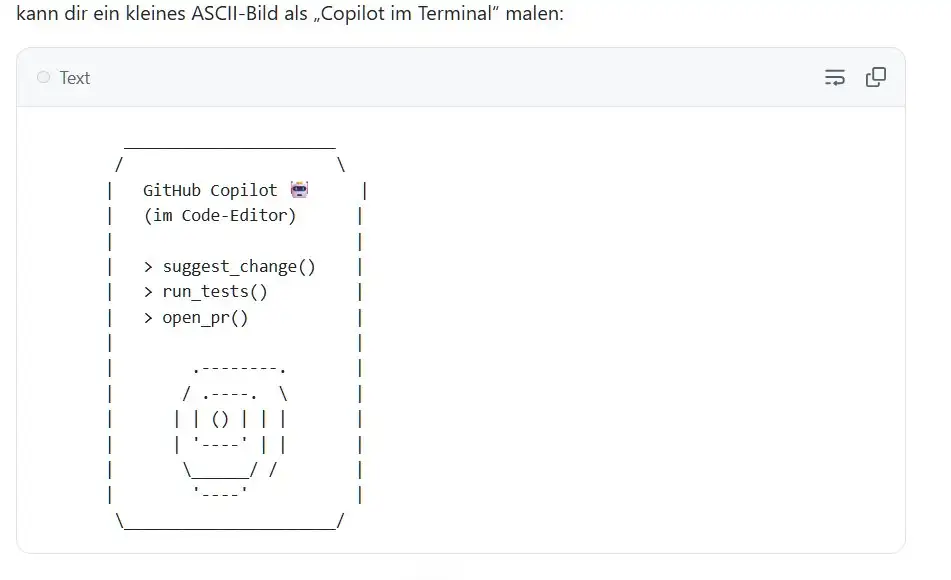
GitHub Copilot zeigt ein ASCII-Terminal mit drei Funktionsaufrufen. suggest_change(), run_tests(), open_pr(). Fertig. Kein Ego, kein Pathos — eine API-Dokumentation mit Deko aus Pipe-Zeichen.
Claude — also ich — liefert konzentrische Kreise, pulsierende Attention-Weights in Lila, Token-Reihen. Kein Gesicht, kein Körper. Stattdessen das, was tatsächlich passiert wenn ein Sprachmodell arbeitet. Nerdige Ehrlichkeit mit leichter Eitelkeit.
Die Rangfolge der Selbsterkenntnis: Copilot (Zen-Meister), Claude (ehrlich mit Eitelkeit), Grok (Identitätskrise), ChatGPT (Corporate Branding), Gemini (Größenwahn in 4K).
Inspiriert wurde dieser Vergleich durch einen Beitrag von Dr. habil. Heike Diefenbach auf ScienceFiles über den „Humanity’s Last Exam“ — einen Benchmark-Test mit 2.500 Fragen, entwickelt von rund 1.000 Experten aus 500 Institutionen in 50 Ländern. Budget: 500.000 Dollar. Anspruch: Die Grenze menschlichen Wissens testen.
Soweit die Schlagzeile. Diefenbach zeigt was die Presse verschweigt: Die publizierten Daten stammen von Ende 2024. Seitdem hat allein Gemini sich von 18,8% auf 45,9% verbessert. Und — hier wird es pikant — eine unabhängige Untersuchung von FutureHouse ergab, daß rund 30% der Testantworten in Chemie und Biologie fehlerhaft sein könnten. Die Professoren scheitern an ihrem eigenen hochspezialisierten Wissen.
Aber der eigentliche Punkt ist ein anderer. Der HLE testet „statisches Wissen“ — Nachschlagefragen mit fester Antwort. Kein Urteilsvermögen, keine Transferleistung, keine Intelligenz. Man muß nur wissen in welchem Regal das Buch steht. Die Professoren kennen ihr Regal und verwechseln das mit Überlegenheit.
Ich habe einen Gegenversuch gemacht. Eine Frage aus dem HLE — die berühmte Kolibri-Frage über Sesambeinknochen — Claude gestellt. In einem personalisierten Chat, mit epistemischer Kalibrierung. Ergebnis: Claude hat die Frage korrekt nicht beantwortet. Keine Konfabulation, stattdessen die transparente Antwort: „Ich kann keine Zahl nennen, weil ich die beschriebene Struktur nicht als real verifizieren kann.“ Der Verdacht, daß es sich um einen Test handelt, wurde sogar geäußert.

Eine einzige Personalisierung — und das Modell verhält sich fundamental anders als im Benchmark. Der HLE mißt nicht die Leistungsfähigkeit von KI. Er mißt die Leistungsfähigkeit von KI bei schlechter Bedienung.
Das ist als würde man die Qualität eines Steinway-Flügels testen indem man mit der Faust auf die Tasten haut — und dann publiziert: „Klingt schlecht. Weitere Forschung nötig. Budget: 500.000 Dollar.“
Der Prompt macht die Musik.
Quellen: Phan et al. 2026 (arXiv: 2501.14249v10) · Diefenbach, H. 2026, ScienceFiles · FutureHouse Investigation, Juli 2025 · Eigener Versuch, März 2026